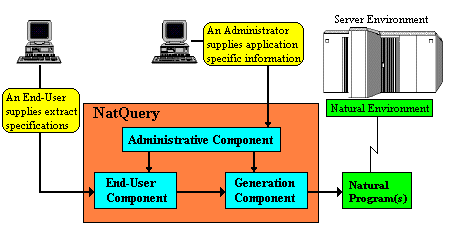
NatQuery is comprised of three primary components:
- An Administrative Component
- An End-user Component, and
- A Generation Component.
To communicate with the remote Natural Server Environment, NatQuery utilizes architecture based on automated FTP (for OS/390, VSE or UNIX platforms) or automated File Copy operations (for Windows Server platforms). Further information on how NatQuery can be automatically integrated to a remote server can be found on the NatQuery Connectivity Architecture page.
The general architecture of the three primary NatQuery components is graphically depicted below.
 |
Administrative Component
The Administrative Component is designed for use by a designated administrator, and it serves to capture basic categories of information about any given application’s file structure; information that is essential for intelligent extraction program generation.
The Administration process begins by customizing templates that will allow for “batch” interaction against the remote Natural Server Environment. For OS/390 or VSE platforms, this batch interaction will be accomplished through the use of JCL templates, for UNIX or Windows, batch interaction takes place through Script templates. Through these JCL / Script templates, NatQuery will gain the ability to both use and make requests against the remote Natural environment.
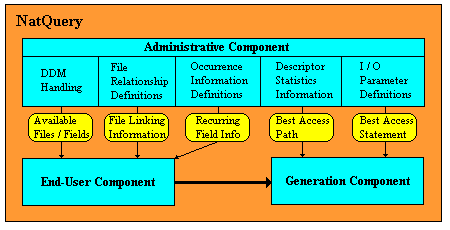
With JCL / Script templates configured, NatQuery is then given Data Definition Modules (DDMs) that contain the basic field information for each of the files that will be opened to extraction or PLOG Processing, with NatQuery being able to either automatically download needed DDMs through batch requests, or through the ability to import DDMs. Once DDMs are imported into NatQuery, an Administrator then utilizes specific administrative functions of NatQuery to define further required information that is based on these DDMs. Specific functions allow for the definition of: :
- File Relationships
This information describes how any given DDM (file) relates to other DDMs, the access paths (keys/indices) that support each specific relationship, and how those keys become initialized. Provided with this information, NatQuery can automatically link related files without further user intervention. - Descriptor Statistics
This information captures all access paths (Descriptors, Super-Descriptors, Sub-Descriptors, Keys, Indices, etc.) available for a given file and describes the I/O dynamics of these paths. This information can either be automatically generated or manually supplied. Provided with this information, NatQuery can automatically determine which access paths can be used, and automatically select the optimal access path. - Occurrence Information
This information describes the default occurrence specifications for recurring fields, as well as their specific maximum limits. If occurrence information has been entered into Predict, and DDMs were generated to include this Occurrence Information , then NatQuery can automatically pick this information up from an imported DDM. Provided with this information, NatQuery can enforce individual limits for the recurring field structures of ADABAS (Periodic-Groups or Multi-Valued Fields), and remove the need of the user to know this information. - I/O Parameters
This information describes program generation limits for when one Natural I/O statement should be generated over another. With these definitions, NatQuery will automatically optimize the data access path to the best I/O statement. - Sign Byte Information
This information describes which fields, if any, require a sign byte when being extracted. By default, NatQuery will assume that all ADABAS fields being output do not require a sign byte (this saves space in the extracted output) however an Administrator can easily indicate which fields should be output with a sign.
With the above information provide once, NatQuery is given "application intelligence" - an intelligence that can be equated to that of a skilled Natural programmer who understands the complexity of a given database application file structure. This intelligence then allows for the generation of optimized single and multi-file data extract programs on demand, in a manner that completely shields the user from the complexities of Natural, ADABAS data structures, JCL / Script or nuances of the Natural / ADABAS platform.
How the Administrative Component interacts with the other two components can be seen in the following graphic:
 |
End-user Component
With Administration functions completed, the problem of resolving a given user's extraction requirements is reduced to its most basic elements:
- What file(s) does the desired data fields reside in,
- What data fields need to be retrieved,
- What additional variable fields (if any) should be added to the extracted data,
- What selection logic (if any) should be applied to retrieve the specified data, and
- How the extract specification should be documented
The end-user component supplies the graphical means of capturing the above information, and with this information a Query Specification is created. Query Specifications can be handled in typical Windows fashion, with the standard functions of Open, Save, Save As, Delete, etc.
Once a Query Specification is created, the user simply requests that the Query be Sent to the Server, at which time the user will indicate where the output is desired. Currently, the following targets and processing are supported:
- Download to PC File
This option allows for data downloads to be delimited (with user specified delimiters) or non-delimited (with the option to create an Offset Report). - Download into Excel
This option allows for data to be download and automatically placed into EXCEL, complete with user-specifiable column headers. - DWH Software Extract
This option allows for extracted data to be immediately integrated to Data Warehousing Extraction, Transformation and Loading (ETL) tools. - Download into Access
This option allows for data to be download and automatically placed into ACCESS, with the ability to create, append or overlay tables. - RDBMS Loading
This option supports the automated integration of ADABAS data directly into popular RDBMS’s. Oracle, MySQL, and Microsoft’s SQL Server are currently supported. - Extraction / Download with ADACMP processing
This option supports one of the fastest ways of unloading an ADABAS file by utilizing the ADABAS utility ADACMP. This function is only available in Administrative versions and when the platform is OS/390 or VSE. - Download into XML
This option allows for extracted data to be download as data to the NatQuery workstation with this data then being transformed into XML with optional XSL. - Extract and Load into DB2
This option allows for extracted data to be directly loaded into DB2 using the DB2 Loader utility. This function is only available in Administrative versions and when the platform is OS/390 or VSE. - Extract to XML on Server
This option supports the conversion of ADABAS data directly into XML in one process on the server platform (XSL generation is not supported however). - Extraction / Download with ADAULD processing
This option supports the ability to extract data either directly from ADABAS or indirectly from ADABAS using an ADABAS Backup (ADASAV) tape as a source. This function is only available in Administrative versions and when the platform is OS/390 or VSE.
Generation Component
The Generation Component is where the “magic” happens, as it is the Generation component that converts a User’s Query Specification into a ready-to-execute extraction process.
From a Query Specification, the Generation Component applies built-in Natural programming intelligence to information obtained through the Administration Component to generate complete, ready-to-execute data extraction requests from ADABAS. The generation capabilities include:
- The generation of all required Natural data processing programs,
- The generation of any required parameters, and
- The generation of any required JCL / Script that will run the process on the Natural / ADABAS server platform.
Whenever a Natural program is generated, the Natural program is generated as Natural 2 structured code that is “Performance Sensitive”. “Performance Sensitive” means that the NatQuery generation engine has the intelligence to:
- Identify all possible access paths that are available to resolve a given query specification (Descriptors, Super-Descriptors, Sub-Descriptors, Hyper-Descriptors, etc.)
- Review each available access path to select the optimal access path with full consideration of any user-supplied selection logic and ADABAS field suppression (which can effect the usability of any given access path for a particular query)
- Determine the appropriate I/O statements necessary to use against the selected file(s), with the ability to automatically generate READ LOGICAL, READ PHYSICAL, FIND and GET statements.
With an extraction process generated, NatQuery can then automatically submit the generated process directly to the remote Natural / ADABAS server platform where it can be automatically executed - with the requesting user then being able to remotely monitor, and then automatically download data requests.
To learn more about how NatQuery integrates to a remote Natural / ADABAS server platform, please refer to the NatQuery Connectivity Architecture page.
